Achieve your Ideal Python Solutions with Our Expert Precision

- Outcome-driven KPIs & reviews
- US, UK & EU delivery experience
- High retention, stable teams
- Ongoing code reviews
- Fast onboarding (4-5 days)
- Pre-vetted senior developers
- Direct developer access
- Flexible engagement models
- Timezone-aligned collaboration
- Strong IP & data security








- 300 + Happy Clients
- 4.9 / 5.0 Overall Clutch Rating
- 400 + Specialists
- 95 % Client Retention Rate
About eSparkBiz
Why eSparkBiz for Python Development Services?

Scalable and Secure Python Solutions for Business Applications
eSparkBiz delivers Python solutions built for enterprise and mid-market applications, focusing on secure architecture and long-term scalability. Global usage trends show Python adoption is highest in the United States with 74,528 users representing 47.20% of demand, followed by India at 11.46% and the United Kingdom at 7.99%.
Our Python developers build high-performance applications using modern frameworks and AI-assisted development practices. We focus on clean code, efficient architecture, and seamless integrations to support automation, data processing, and scalable business applications across different industries and use cases.
How eSparkBiz Delivers High-Quality Python Solutions:
- Scalable application development using modern Python Web Frameworks
- Secure Python Integration across APIs and enterprise systems
- Continuous testing aligned with performance and security benchmarks
Success Stories

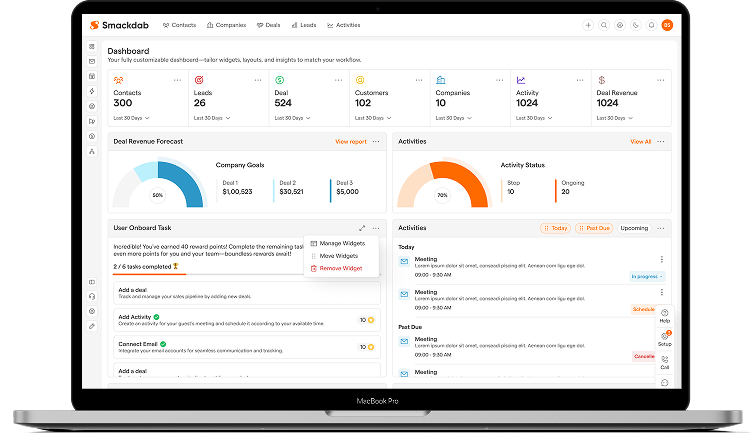
SmackDab – AI-Powered CRM Platform
SmackDab delivers an intelligent CRM experience that streamlines sales operations through centralized administration, actionable analytics, and AI-driven automation.
- Engagement Model Staff Augmentation
- Engagement length 48+ Months
- Market Stage Live & Scaling
- Team Member 20+ Team Members
- Services Provided End-to-End Product Enginerring

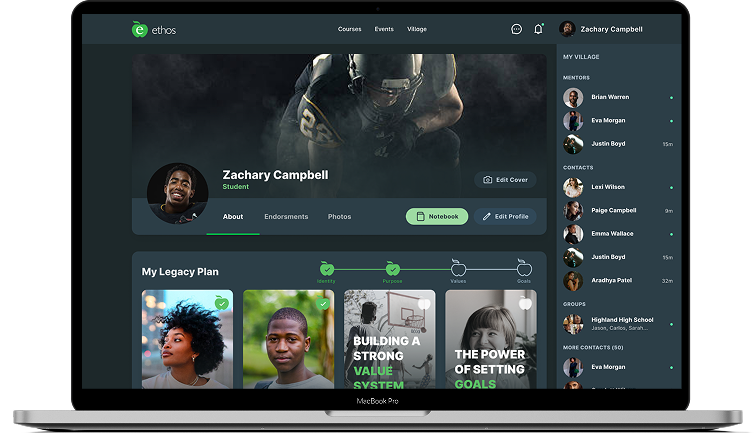
Ethos Village – Learning & Mentorship Ecosystem
Ethos Village is an educational web-based platform with various courses and activities to enrich users' lives and aid in the discovery of goals and purposes. On a single platform, different…
- Engagement Model Staff Augmentation
- Engagement Length 24+ Months
- Market Stage Live & Scaling
- Team Members 5+ Team Members
- Services Provided End-to-End Product Engineering

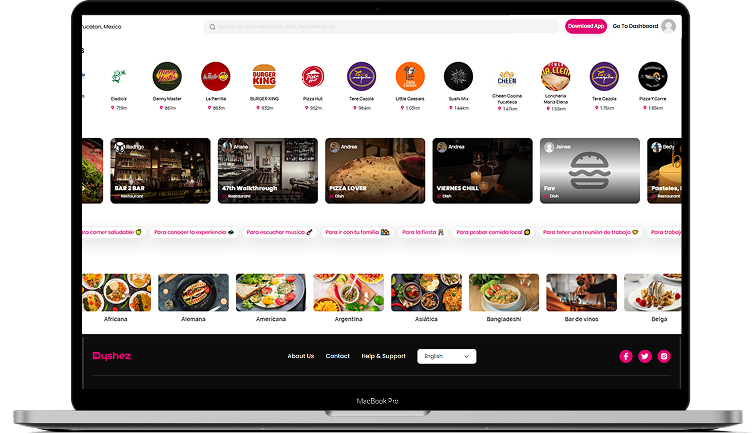
Dyshez – Digital Food Service Platform
Dyshez stands as a revolutionary Restaurant Management force in the realm of dining applications, ushering in a transformative era in the culinary landscape. Far more than a mere app, Dyshez…
- Engagement Model Staff Augmentation
- Engagement Length Long-Term Engagement
- Market Stage Live & Scaling
- Team Member 6+ Team Members
- Services Provided End-to-End Product Engineering

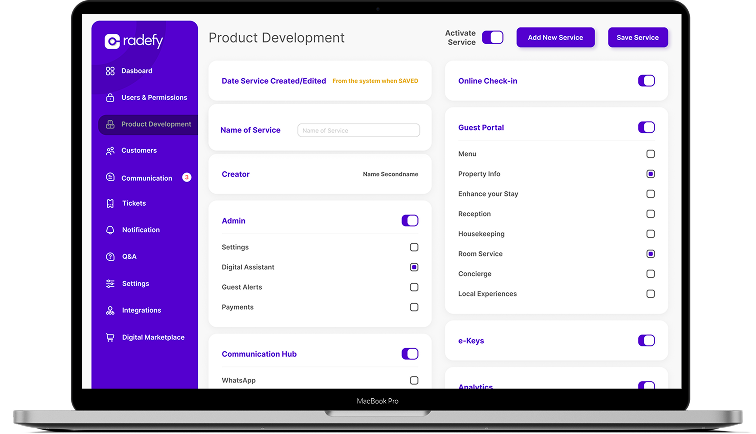
Radefy – IoT Guest Experience Platform
Radefy is revolutionizing the hospitality industry by harnessing the power of IoT smart devices to create unparalleled guest experiences. With our cutting-edge technology and forward-thinking approach, we are transforming traditional…
- Engagement Model Hire Dedicated Development Team
- Engagement Length 24+ Months
- Market Stage Growth & Scaling Phase
- Team Member 4+ Team Members
- Services Provided PMS Integration & Hospitality API Integration Services

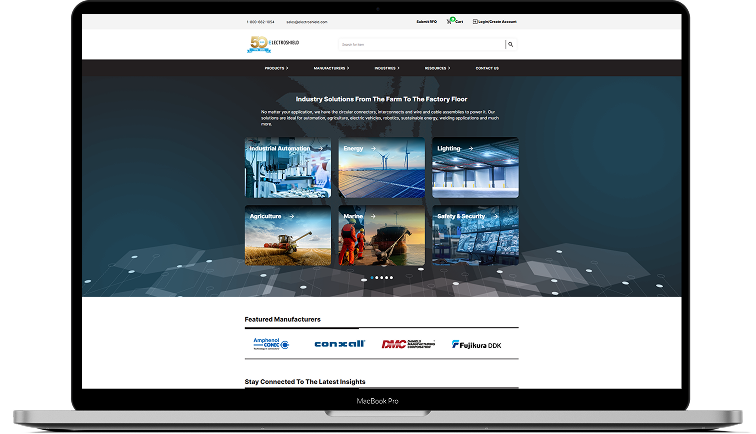
ElectroShield – Smart Shopping Platform
Cutting-edge e-commerce platform, ElectroShield is for electronic connectors and products. Seamless shopping with buy and RFQ functions. Extensive product line, hassle-free checkout, and customizable content management system for a top-notch…
- Engagement Model Staff Augmentation
- Engagement Length 12+ Months
- Market Stage Live & Scaling
- Team Member 6+ Team Members
- Services Provided End-to-End Product Engineering
Review Proven Work that delivers Measurable Outcomes and reflects Our Engineering Excellence across complex high-impact initiatives.
End-to-end Python Development Services
What Organizations gain from eSparkBiz Python Development Services?
Our Python development services help organizations improve system efficiency, accelerate integration workflows, modernize applications and deliver software aligned with real operational and business requirements.
Custom Python App Development
- Custom Python App Development
- Python Web Development
- Python Backend Development
- API Development and Integration
- Automation and Scripting
- Data Engineering and Analytics
- Cloud-Based App Development
- App Migration and Modernization
- Quality Assurance and Testing
- Support and Maintenance

Custom Python Application Development
At eSparkBiz, we build tailored Python applications with clear ownership, aligning business workflows and product goals through structured custom software development practices.
What We Deliver:
- Business-specific application logic
- Modular architecture planning
- Backend workflow engineering
- Deployment readiness

Python Web Development
We develop Python-based web solutions with a focus on usability and maintainability, supporting modern web application development across customer-facing and internal platforms.
Service Highlights:
- Server-side web logic
- Framework-based development
- Request handling workflows
- Python Performance optimization

Python Backend Development
Our backend development services use Python to manage application logic and data processing, delivering reliable system behavior across complex digital platforms.
Core Capabilities:
- Business logic implementation
- Database interaction layers
- Service orchestration
- Performance tuning

Python API Development and Integration
We design Python APIs with clear data contracts, enabling smooth communication between applications and reliable integration with Python-based backends and frontend interfaces built using Angular.
Key Focus Areas:
- REST API development
- Third-party integrations
- Data exchange workflows
- Authentication handling

Python Automation and Scripting
With Python Automation, we help reduce manual effort by streamlining repetitive tasks, operational processes and routine system workflows.
Automation Use Cases:
- Task automation scripts
- Workflow optimization
- Data processing jobs
- System maintenance tools

Python Data Engineering and Analytics Solutions
Our data analytics services support structured data processing with Python, helping organizations analyze operational datasets and prepare reliable inputs for analytics.
Data Capabilities:
- Data pipeline development
- Data processing logic
- Analytics preparation
- Reporting support

Python Cloud-Based Application Development
We develop Python applications for cloud environments, working with flexible deployment models and resource configurations to support distributed application architectures.
Cloud Readiness:
- Cloud-native architecture design
- Deployment configuration support
- Environment optimization
- Resource utilization planning

Python Application Migration and Modernization
With a structured Python development approach, we modernize applications by improving architecture, updating dependencies and transitioning legacy systems to current technology standards.
Modernization Focus:
- Legacy code assessment
- Architecture refactoring
- Platform upgrades
- Compatibility improvements

Python Quality Assurance and Testing
Our testing services validate Python applications through structured Software testing and QA processes, ensuring functional accuracy and reliable system behavior.
Testing Coverage:
- Functional validation
- Regression testing
- Performance verification
- Defect resolution

Python Support and Maintenance Services
We provide ongoing Python support with regular monitoring, issue resolution and updates to help maintain application stability and operational continuity.
Support Scope:
- Issue monitoring
- Performance reviews
- Version updates
- Technical assistance

Why Partner
Why Partner with eSparkBiz?
As a Python development company, we help businesses deliver dependable software solutions and also support teams that want to hire Python developers backed by proven engineering practices and domain understanding.
-
Adherence to ISO 9001 and CMMI Level 3 quality standards
-
A delivery team of skilled professionals across software engineering disciplines
-
Engineering expertise spanning backend, AI/ML, frontend and cloud systems
-
Experience delivering Python solutions for clients across 20+ countries
-
Recognized for Proven Python Development Practices
- Listed by TopDevelopers for Python development excellence
- Ranked by Gartner as Trusted Custom Software Development Providers
- Named among Clutch’s 1000 Top Rated Business Service Providers
- Featured by Business Talk among India's Python Development Companies
- Client reviews and ratings published on Clutch, GoodFirms, G2 and HubSpot
 15+ Years of Expertise
15+ Years of Expertise  100% NDA-protected Contract
100% NDA-protected Contract  95% Client Retention Rate
95% Client Retention Rate  Access to 45+ Technologies
Access to 45+ Technologies Certification

Delivering Standardized Software Solutions

Delivering Standardized Software Solutions
Delivering Standardized Software Solutions
Delivering Standardized Software Solutions
Delivering Standardized Software Solutions
Delivering Standardized Software Solutions

Delivering Standardized Software Solutions
Next-Gen Python Use Cases

AI Applications
Teams leverage Python to design AI applications, where we combine domain insight with AI consulting practices, enabling intelligent features, decision support and responsible automation that aligns technical outcomes with real business objectives.

Machine Learning
Organizations adopt Python for machine learning solutions, as our engineers focus on machine learning development with practical models, data pipelines and evaluation methods that support accuracy, security, scalability and continuous improvement.

Data Analytics
Businesses use Python for data analytics initiatives, starting with structured data processing, where we apply statistical techniques, visualization tactics and reporting workflows to turn raw information into actionable, operational insightful decisions.

Web Platforms
Product teams rely on Python for building web platforms, beginning with backend logic, as we support web development efforts through scalable architectures, secure integrations and performance-focused implementations for modern digital experiences.

Automation Systems
Operations teams implement Python-driven automation systems, often with our guidance, where AI Agent Development enables task orchestration, decision workflows and adaptive processes that reduce manual effort and improve operational consistency.

API Development
Engineering groups choose Python for API development projects, starting from service design, as we focus on clear contracts, reliable API integrations and maintainable endpoints that supports long-term application interoperability and assured scalability.

Cloud Applications
Technology leaders adopt Python for cloud applications, approaching cloud application development with flexible deployment models, as our teams design services that scale efficiently across distributed environments and evolving infrastructure demands.

Healthcare Systems
Healthcare organizations apply Python within healthcare systems, beginning with compliance-aware design, where we support healthcare software development by enabling secure data handling, system interoperability and analytics-driven workflows for clinical and operational use.
Turn Your Vision into Futuristic Reality with Our Advanced Python Expertise

Tech Stack
Technologies Powering Our Python Development Solutions
Our Python solutions are built on carefully selected technologies and frameworks, enabling efficient development, adaptability and consistent performance across diverse application requirements.
- Frontend
- Backend
- Mobile
- Desktop
- Database
eSparkBiz uses Angular to create dynamic, responsive web applications that deliver high performance and a great user experience.
Practice
8+
Workforce
60+
Leveraging React.js, we build interactive and highly-scalable web app solutions with the ability to attain optimized performance seamlessly.
Having Vue.js in our pocket, we can build progressing web interfaces that perform better and are maintainable.
eSparkBiz uses Next.js to build server rendered React applications to boost performance and SEO optimization.
We’re experts at building ambitious web applications with rich user interfaces and solid functionality with Ember.js.
HTML5 is used by eSparkBiz to display and present content on the web in a structured manner so that it can be compatible and responsive to all sorts of devices.
With Meteor, we can quickly build real time web and mobile applications that sync data easily.
With our CSS3 proficiency, we can build responsive, attractive web interfaces for the user to interact and engage with.
With our JavaScript expertise we are able to build dynamic, interactive web applications that improve user engagement and functionality.
Using .NET, eSparkBiz develops scalable and high performance applications for your business needs that are seamlessly integrated and secured.
Java is used by eSparkBiz to build applications that are platform independent, scalable and reliable for enterprise solutions.
With Python we can make beautiful, versatile apps like web or data analysis apps, with clean and easy to maintain code.
Node.js brings scalability to network applications that can handle asynchronous jobs effortlessly.
Dynamic web applications are developed using PHP which enables us to use server side scripting and robust functionality in your websites.
With our experience in Go, we are able to create fast, high performance backend services with good concurrency and scalability.
Taking advantage of Android's versatility, we build user friendly mobile applications with excellent user experience on different devices and platforms.
Using the latest technologies, we create mobile apps that offer smart user experiences.
At eSparkBiz, we build Progressive Web Apps that offer the best of both worlds, web apps and mobile apps, with offline functionality and enhanced user experience.
Workforce
40+
React Native is used by eSparkBiz to build mobile applications with a native look and feel that will also result in 50% faster development cycles.
eSparkBiz develops natively compiled applications for mobile, web, and desktop from a single codebase using Flutter and it improves development efficiency.
For developing cross platform mobile apps, we use Cordova to guarantee the same functionality and experience of the apps on different devices.
With Ionic, we’re able to create high quality cross-platform mobile applications while retaining native performance and user experience.
We can create modern, concise and safe Android applications using our Kotlin proficiency and bring us code quality and maintainability.
At eSparkBiz, we develop applications in Swift that produce high performance, safe and expressive code for iOS and macOS platforms.
SwiftUI is a platform for building user interfaces for Apple platforms, and we're experts at it: declarative syntax and seamless integration are what we do.
We are experts in Xamarin, and build cross platform mobile apps that can run on a single codebase with native performance and UI.
With our knowledge of C++, we develop high performance software solutions for optimized resource management and system level programming with complex applications.
Having .NET Framework expertise, we can develop enterprise grade solutions that improve operational efficiency and help business growth.
At eSparkBiz, we use C# to build robust and scalable applications that can be easily integrated and provide high performance on multiple platforms.
Using Qt, we can make native performance, cross platform applications with consistent user experience on multiple operating systems.
Being experts with Objective C, we can develop robust iOS applications with the ability to work with legacy code bases.
In React Native applications, we use Async Storage to manage persistent data, so that our applications can work efficiently offline, and give a better user experience.
We use Azure SQL Database to offer scalable, high performing data solutions that ensure your applications have secure and effective data management.
Cassandra’s distributed database capabilities allow us to manage large scale data workloads and provide high availability and scalability for your applications.
In iOS applications, eSparkBiz implements Core Data for efficient data persistence improving performance and data management.
DynamoDB is something we know very well, so we can build scalable, low latency data solutions with high availability for your applications.
With Firebase, we have the know-how to make real time apps, seamlessly syncing data and authenticating users.
For real time NoSQL database management, we use Firestore to store and retrieve data in your applications efficiently.
With our experience with Apache Hive, we are able to query and analyze large datasets quickly and make data-driven decisions.
Using MongoDB, we can create flexible and scalable NoSQL databases that fit your needs for data models.
For building reliable, high performance relational databases, we use MySQL to efficiently manage your data.
eSparkBiz uses Oracle databases to handle complex data environments to provide high performance, scalability and robust security to your enterprise applications.
PostgreSQL is used by eSparkBiz to build advanced open source relational databases with extensibility and SQL compliance for complex applications.
We know Realm and can put that knowledge to use to build mobile databases that are efficient, real time, and offline capable.
We use Redis to store in memory data structures and get high speed data retrieval and application responsiveness.
To supply lightweight, disk-based databases for mobile and embedded applications, we use SQLite.
In React Native applications, we use WatermelonDB for complex data persistence, providing high performance with large datasets.
Step-by-step Process
How Python Projects are delivered at eSparkBiz?
Understand how Python projects are executed in real-world environments, including workflows that support AI with Python applications, system integrations and reliable software delivery outcomes.
Requirement Analysis
At this stage, we work with stakeholders to understand business objectives, technical constraints and integration needs, forming a clear foundation for accurate planning.
Key Activities
- Business objective alignment
- Stakeholder requirement mapping
- Technical feasibility assessment
How It Works
Requirements are documented and validated early, helping teams reduce confusion and ensure decisions align with agreed project goals.
Requirement Analysis
Solution Planning
After requirements are confirmed, we shape a practical plan with defined scope, timelines and responsibilities, ensuring technical decisions remain aligned with delivery constraints.
Key Activities
- Scope and milestone definition
- Technology stack selection
- Resource and timeline planning
What Matters Here
Planning emphasizes realistic estimation and early alignment, helping teams minimize rework while keeping architectural choices compatible with integration needs and long-term maintainability.
Solution Planning
System Design
We shape system design with clear structures, defining architecture, data relationships and UI/UX design flows, working with product goals to guide consistent and usable development.
Key Activities
- System architecture definition
- Data flow modeling
- Interface structure planning
What Drives Design
Design decisions focus on clarity and usability, ensuring technical structures and interface choices remain practical, extensible and aligned with development constraints and integration requirements.
System Design
Development Execution
With approved designs in place, development execution focuses on building features, APIs and integrations using current stable Python versions to ensure consistency, compatibility and reliable functionality.
Key Activities
- Feature implementation workflows
- Backend logic development
- API integration execution
What Drives Execution
Execution emphasizes practical coding standards and controlled implementation, helping teams deliver maintainable functionality that aligns with system design and supports effective validation.
Development Execution
Quality Validation
Our quality validation process verifies application behavior, performance and reliability through structured testing activities that confirm systems operate correctly under expected usage conditions.
Key Activities
- Functional testing coverage
- Integration testing checks
- Performance and stability validation
Which Quality Checks Matter
Validation emphasizes repeatable testing and early issue identification, helping teams address defects systematically and prepare software for dependable production deployment.
Quality Validation
Deployment Support
Our deployment support ensures applications are launched smoothly and remain operational through controlled rollouts, environment configuration and post-deployment assistance.
Key Activities
- Production deployment coordination
- Environment configuration management
- Post-release issue handling
Which Deployment Aspects Matter
Support prioritizes stability and continuity, helping teams address early operational issues, apply updates safely and maintain consistent system performance after release.
Deployment Support
Ready to Streamline Your Python Development Approach?
Engagement Model
What Engagement Models we offer for Python Development?
We deliver Python development through flexible engagement approaches, integrating AI-driven processes to ensure scalability, security, and tailored solutions that align with diverse business objectives.

Full-Cycle Outsourcing
Full-cycle outsourcing covers complete project ownership, including planning, development, deployment and ongoing support, allowing organizations to rely on a single team for end-to-end Python delivery.

Dedicated Python Teams
Dedicated Python teams work as an extension of your organization, aligning with internal processes and priorities while providing consistent engineering capacity for continuous development initiatives.

Python Team Augmentation
Python team augmentation strengthens existing in-house teams by adding experienced Python specialists, helping accelerate delivery and address skill gaps without altering established workflows.
Accelerate your Python Development Roadmap with the Right Engagement Model
Client Testimonials
Our Clients Say About Us
We focus on making clients happy and always appreciate their opinions. We aim to provide superior services to earn trust and to become a go-to choice in the industry.
FAQs
Frequently Asked Questions
We address certain queries related to Python development, displaying our technical prowess and proven ability, and how eSparkBiz implements high-performance, scalable Python solutions in different industry spheres.
What does a Python development company do?
A Python development company designs, builds and maintains software applications using Python for web platforms, data processing, automation and AI-driven systems.
How much does Python development cost?
Python development costs typically range between $12–$25 per hour, depending on project scope, expertise and region, with eSparkBiz offering services within this range.
Why is Python widely used for AI and machine learning projects?
Python is widely used for AI and machine learning due to its extensive libraries, readable syntax and strong ecosystem supporting data modeling and experimentation.
How many live websites in the United States use Python?
According to BuiltWith, 40,006 live websites in the United States currently use Python-based technologies.
How long does it take to build a Python application?
Most Python applications take 8–16 weeks to develop, depending on complexity and scope, while eSparkBiz typically completes project onboarding within 4–5 business days.
What industries commonly use Python development services?
Python development services are widely used across healthcare, finance, eCommerce, SaaS, education, logistics and data-driven enterprise applications.
How do companies choose the right Python development partner?
Which are the top Python development companies?
Top Python development companies include eSparkBiz, ClearSummit, Andersen and Ravn, evaluated based on expertise, delivery quality and client feedback.
Expert Insights
Expert Insights for Python Development
Extend, Build, and Scale with eSparkBiz
Deliver reliable software solutions with dedicated teams, flexible models, and secure development practices.
- AI-Enabled Engineering
- 400+ Skilled Developers
- Flexible Engagement Models
- Time Zone Aligned Delivery
- Enterprise-Grade Security

Ready to Scale Your Engineering Team?
Extend your development capacity with pre-vetted engineers and dedicated teams.

48-72 Hrs
Developer Onboarding

Flexible
Engagement Models

Trial
Engagement Available

