Turn Underperforming Language Models into High-Impact AI Systems Through Custom LLM Fine-Tuning

- Proprietary Data Training
- GPT & Llama Customization
- 3X Faster Model Training
- LoRA & QLoRA Expertise
- Workflow-Aware Models
- Production-Ready Deployments
- Domain Knowledge Integration
- 50% Lower Inference Costs
- 4-Week Delivery Framework
- Human-Guided Model Evaluation








- 300 + Happy Clients
- 4.9 / 5.0 Overall Clutch Rating
- 400 + Specialists
- 95 % Client Retention Rate
End-to-End Product Development
Discovery • Design • Develop • DeployAbout eSparkBiz
Why eSparkBiz for LLM Fine-Tuning Services?

Creating Enterprise AI That Learns Your Language, Processes, and Expertise
Generic LLMs often struggle to understand proprietary business knowledge, industry terminology, and tailored workflows, leading to inconsistent outputs and reduced adoption. At eSparkBiz, our AI engineers fine-tune foundation models using domain-specific datasets, helping organizations build AI systems that perform reliably in real-world business environments.
As commercials move from experimentation to production AI, demand for customized language models continues to rise. Industry forecasts project the LLM fine-tuning services market to reach $22.8 billion by 2034, reflecting the growing need for AI systems tailored to unique workflow needs and business objectives.
How Does eSparkBiz Turn Generic LLMs into Business-Critical AI Systems?
- 4-Week Fine-Tuning Engagements
- Custom Training Data Optimization
- 10+ LLM Adaptation Techniques
- Business-Grade AI Governance Controls
Our Featured Work

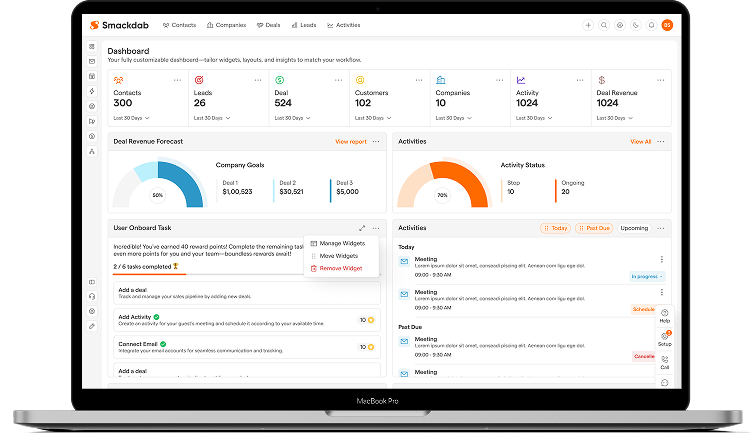
SmackDab – AI-Powered CRM Platform
SmackDab delivers an intelligent CRM experience that streamlines sales operations through centralized administration, actionable analytics, and AI-driven automation.
- Engagement Model Staff Augmentation
- Engagement length 48+ Months
- Market Stage Live & Scaling
- Team Member 20+ Team Members
- Services Provided End-to-End Product Enginerring

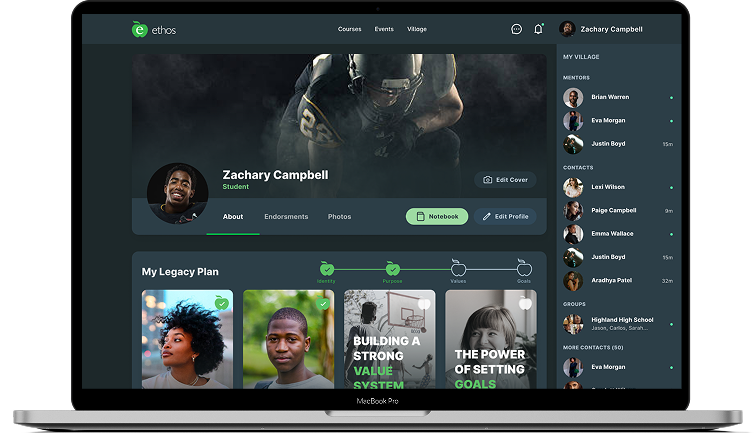
Ethos Village – Learning & Mentorship Ecosystem
Ethos Village is an educational web-based platform with various courses and activities to enrich users' lives and aid in the discovery of goals and purposes. On a single platform, different…
- Engagement Model Staff Augmentation
- Engagement Length 24+ Months
- Market Stage Live & Scaling
- Team Members 5+ Team Members
- Services Provided End-to-End Product Engineering

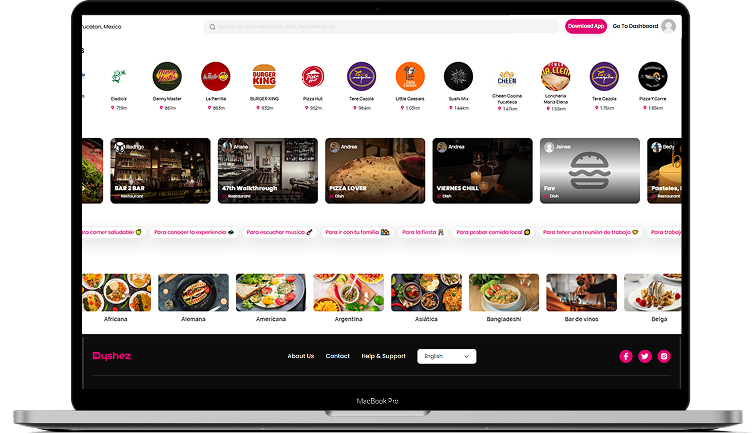
Dyshez – Digital Food Service Platform
Dyshez stands as a revolutionary Restaurant Management force in the realm of dining applications, ushering in a transformative era in the culinary landscape. Far more than a mere app, Dyshez…
- Engagement Model Staff Augmentation
- Engagement Length Long-Term Engagement
- Market Stage Live & Scaling
- Team Member 6+ Team Members
- Services Provided End-to-End Product Engineering

Radefy – IoT Guest Experience Platform
Radefy is revolutionizing the hospitality industry by harnessing the power of IoT smart devices to create unparalleled guest experiences. With our cutting-edge technology and forward-thinking approach, we are transforming traditional…
- Engagement Model Hire Dedicated Development Team
- Engagement Length 24+ Months
- Market Stage Growth & Scaling Phase
- Team Member 4+ Team Members
- Services Provided PMS Integration & Hospitality API Integration Services

ElectroShield – Smart Shopping Platform
Cutting-edge e-commerce platform, ElectroShield is for electronic connectors and products. Seamless shopping with buy and RFQ functions. Extensive product line, hassle-free checkout, and customizable content management system for a top-notch…
- Engagement Model Staff Augmentation
- Engagement Length 12+ Months
- Market Stage Live & Scaling
- Team Member 6+ Team Members
- Services Provided End-to-End Product Engineering
Review Proven Work that delivers Measurable Outcomes and reflects Our Engineering Excellence across complex high-impact initiatives.
End-to-end LLM Fine-Tuning Services
Which LLM Fine-Tuning Services Does eSparkBiz Offer?
Organizations often face inconsistent AI outputs that limit business impact. eSparkBiz fine-tunes foundation models to deliver more dependable and customized performance.
Custom LLM Fine-Tuning
- Custom LLM Fine-Tuning
- GPT Model Fine-Tuning
- Llama Model Fine-Tuning
- Domain-Specific Training
- Training Data Engineering
- Model Performance Optimization
- RAG Integration Services
- LLM Deployment & MLOps

Custom LLM Fine-Tuning
Business-critical AI often falls short when generic models are expected to handle dedicated tasks. At eSparkBiz, we tailor LLM behavior around unique requirements, enabling more dependable outcomes across complex environments.
What We Deliver:
- Task-Specific Learning
- Proprietary Data Adaptation
- Response Quality Enhancement
- Performance-Focused Optimization

GPT Model Fine-Tuning
Getting consistent value from GPT models can be difficult when outputs fail to reflect organizational expertise. Our AI software engineers customize model behavior, helping teams achieve greater precision and stronger adoption.
Customization Focus Areas:
- OpenAI Model Expertise
- Brand Voice Alignment
- Business Knowledge Training
- Controlled Output Behavior

Llama Model Fine-Tuning
Organizations seeking greater control over AI infrastructure often choose open-source models. Through niche expertise, we adapt Llama architectures to support secure deployments, flexible customization, and long-term scalability.
Core Capabilities Included:
- Open-Source Flexibility
- Enterprise Deployment Support
- Private AI Workloads
- Cost-Efficient Customization

Domain-Specific Training
Specialized applications demand more than general-purpose intelligence. By combining industry knowledge with model training, our team develops AI systems capable of supporting highly focused service requirements.
Knowledge Areas Covered:
- Industry Knowledge Mapping
- Specific Terminology Learning
- Context-Rich Intelligence
- Purpose-Built AI Systems

Training Data Engineering
Even advanced models struggle when training datasets contain inconsistencies or irrelevant information. The eSparkBiz team prepares and structures data to create stronger foundations for successful model adaptation and learning.
Data Preparation Scope:
- Data Quality Assessment
- Annotation Workflows
- Dataset Structuring
- Knowledge Extraction Support

Model Performance Optimization
Initial training is only part of the journey. Drawing on extensive optimization experience, our experts identify performance gaps and implement refinements that support sustainable improvements over time.
Performance Enhancement Areas:
- Accuracy Improvement Strategies
- Output Consistency Controls
- Resource Efficiency Gains
- Continuous Performance Refinement

RAG Integration Services
Many organizations require both retrieval capabilities and customized model behavior to meet evolving demands. Leveraging proven implementation frameworks, we combine RAG systems with fine-tuned models to enhance response quality and knowledge accessibility.
Integration Advantages Offered:
- Knowledge Retrieval Enhancement
- Hybrid AI Architectures
- Dynamic Information Access
- Contextual Response Generation

LLM Deployment & MLOps
Moving AI from experimentation to production introduces operational complexities that can delay adoption. With a focus on long-term reliability, our specialists manage deployment, monitoring, and lifecycle operations across production environments.
Operational Support Coverage:
- Production Environment Readiness
- Model Monitoring Frameworks
- Scalable Infrastructure Management
- Lifecycle Performance Governance

Why Partner
Why eSparkBiz Is the Right Partner for LLM Fine-Tuning
Many AI initiatives struggle to move beyond generic outputs and deliver meaningful business value. With AI Expertise at eSparkBiz, we fine-tune LLMs to support advanced requirements, improve relevance, and enable more dependable AI performance.
-
Custom LLM Adaptation for Specialized Requirements
-
60% Reduction in Manual AI Workflows
-
Enterprise-Ready Security, Governance, and Compliance
-
End-to-End Fine-Tuning, Deployment, and Optimization Support
-
35% AI Engineers Powering Custom LLM Initiatives
- Featured Among India’s Leading AI Solution Providers
- Listed Among India’s Most Reviewed Artificial Intelligence Companies
- Recognized by DesignRush for Expertise in AI Governance and Compliance
- Acknowledged as a Trusted Partner for AI Staff Augmentation
- Named Among the Top AI and ERP Transformation Consultants
- Trusted Across Gartner, Clutch, G2, and HubSpot for Enterprise AI Solutions -
Turn Underperforming Models into Reliable Business Assets
-
Bridge Knowledge Gaps Holding AI Initiatives Back
-
Reduce Adoption Barriers created by Generic Model Behavior
-
Move Beyond Experimentation with Production-ready AI Systems
 15+ Years of Expertise
15+ Years of Expertise  100% NDA-protected Contract
100% NDA-protected Contract  95% Client Retention Rate
95% Client Retention Rate  Access to 45+ Technologies
Access to 45+ Technologies Certification

Delivering Standardized Software Solutions

Delivering Standardized Software Solutions

Delivering Standardized Software Solutions

Delivering Standardized Software Solutions

Delivering Standardized Software Solutions

Delivering Standardized Software Solutions

Delivering Standardized Software Solutions
What Is LLM Fine-Tuning: How It Works and Why It Matters
Many organizations struggle when foundation models fail to reflect internal expertise, curated terminology, or task-specific expectations. This often leads to inconsistent outputs, lower confidence, and limited value from AI investments despite significant implementation efforts.
LLM fine-tuning addresses these challenges by training pretrained models on curated datasets, enabling them to better understand organizational knowledge, adapt to specific objectives, and deliver more relevant outputs across targeted applications.
How eSparkBiz Accelerates LLM Specialization?
- Aligns Models with Organizational Knowledge
- Adapts AI for Crafted Requirements
- 10+ LLM Adaptation Techniques
- Strengthens Contextual Response Relevance
- Improves Consistency Across AI Interactions
- 5-Stage Model Refinement Process
- Optimizes Learning Through Curated Datasets
- Enables Production-Ready AI Performance
Transform Business Excellence with Our Niche LLM Fine-Tuning knowledge & expertise
LLM Fine-Tuning Needs

Limited Domain-Knowledge
AI often misinterprets selective subject matter, forcing teams to correct responses and reducing confidence in automated decision-making.
We Build Deeper Understanding:
- Industry Language Training
- Knowledge Gap Reduction
- Subject Matter Learning
- Context-Rich Outputs

Inconsistent AI Outputs
When identical requests produce varying answers, organizations struggle to establish trust and scale AI across departments.
Our Goal Is Predictability:
- Response Standardization
- Output Stability Controls
- Repeatable AI Behavior
- Trusted User Experiences

Prompt Dependency Issues
Teams frequently spend excessive effort rewriting prompts, creating bottlenecks that slow adoption and limit long-term scalability.
We Simplify AI Usage:
- Reduced Prompt Rewrites
- Faster User Adoption
- Streamlined AI Interaction
- Sustainable AI Scaling

Proprietary Data Requirements
Internal documentation and institutional knowledge often remain inaccessible, preventing AI from reflecting how the organization actually operates.
Our Methods offer Value:
- Internal Knowledge Utilization
- Documentation-Based Learning
- Proprietary Information Modeling
- Organization-Specific Intelligence

Complex Business Workflows
Multi-step processes can overwhelm standard models, creating friction where precision and procedural understanding are essential
We Adapt For Complexity:
- Process-Aware Intelligence
- Multi-Step Task Handling
- Structured Decision Logic
- Operational Flow Learning

Accuracy-Critical Applications
Errors in regulated or high-impact scenarios can create costly consequences, making dependable AI behavior a business necessity.
Our Team Mitigates Risk:
- Precision Training Methods
- Error Reduction Strategies
- Governance-Oriented Development
- Confidence-Driven Outcomes
Identify the fastest path to specialized AI performance with guidance from experienced LLM engineers.
Strategic Benefits
What Business Value does LLM Fine-Tuning Deliver?
Many organizations struggle to translate AI investments into meaningful outcomes. At eSparkBiz, we fine-tune LLMs to create measurable improvements across critical business functions.
- Context-Aware Intelligence
- Enhanced Decision Support
- Predictable Behavior
- Faster Execution
- Higher Adoption
- Stronger Business Outcomes
Context-Aware Intelligence
Important details are often overlooked when AI lacks situational understanding. Refined through extensive model training, outputs better reflect the information users actually need.
Enhanced Decision Support
Incomplete insights can make business decisions slower and less certain. Shaped around practical implementation experience, AI delivers guidance with greater relevance.
Predictable Behavior
Unexpected responses frequently create hesitation among teams and stakeholders. Developed with long-term usability in mind, model interactions remain more dependable.
Faster Execution
Routine tasks can consume valuable time when processes remain heavily manual. Built around real operational demands, AI helps accelerate everyday activities.
Higher Adoption
Users rarely embrace AI that feels disconnected from their expectations. Specialists across eSparkBiz help shape experiences that encourage broader engagement across business functions.
Stronger Business Outcomes
Technology investments often struggle to produce measurable returns. Driven by production-focused AI engineering, fine-tuned models contribute to more meaningful results.
See how fine-tuned LLMs can address your specific requirements and deliver greater value across critical business operations.

Industries We Serve
Financial Services

Financial institutions often manage large volumes of sensitive information while navigating strict oversight requirements. Our specialists help create AI systems suited for complex financial operations and informed decision-making.
Risk-Aware Intelligence:
- Regulatory Knowledge
- Fraud Detection
- Financial Research
- Policy Interpretation
Healthcare Sciences

Healthcare organizations depend on accurate information handling where delays can impact operational efficiency. With extensive AI delivery experience, our team supports specialized healthcare applications and knowledge-intensive workflows.
Care-Driven Intelligence:
- Clinical Documentation
- Medical Knowledge
- Patient Support
- Research Assistance
Legal Compliance

Legal teams frequently spend significant time reviewing documents and interpreting obligations across changing regulations. Drawing on practical implementation experience, we support AI applications designed for legal environments.
Compliance-Focused Assistance:
- Contract Analysis
- Regulatory Monitoring
- Legal Summaries
- Policy Reviews
Software Platforms

Growing software products require AI capabilities that align with evolving user expectations and technical requirements. The eSparkBiz team develops solutions that integrate naturally into modern digital experiences.
Product-Centric Innovation:
- User Assistance
- Technical Guidance
- Knowledge Access
- Feature Discovery
eCommerce Retail

Customer expectations continue rising as brands compete to deliver relevant experiences across multiple channels. Our experts help shape AI capabilities that strengthen engagement and purchasing journeys.
Commerce-Focused Experiences:
- Product Discovery
- Customer Assistance
- Catalog Intelligence
- Shopping Guidance
Supply Chain

Operational networks often involve numerous moving parts, making visibility and coordination increasingly difficult. Backed by cross-industry expertise, we support AI solutions that assist with planning and execution.
Operations-Driven Efficiency:
- Inventory Visibility
- Demand Forecasting
- Logistics Support
- Process Coordination
Core Expertise
Turn Your Vision into Futuristic Reality with Our Advanced LLM Fine-Tuning Expertise

eSparkBiz vs Deviniti vs Xenoss
Why eSparkBiz Stands Out among Other Leading Providers for LLM Fine-Tuning Services
Different providers support different AI priorities and delivery models. eSparkBiz focuses on LLM fine-tuning, deployment, and model optimization for organizations seeking business-specific AI capabilities.
| Evaluation Area | eSparkBiz Best Fit | Deviniti | Xenoss |
|---|---|---|---|
| Best Fit For | Organizations seeking:- - LLM fine-tuning |
Enterprises focused on:- - AI adoption |
Businesses investing in:- - AI engineering |
| Hourly Rate Range | $12–$49/hr |
$50–$99/hr |
$50–$99/hr |
| Primary Focus | LLM fine-tuning services, AI agents, RAG integration, and model adaptation |
Enterprise AI applications, process automation, and conversational solutions |
AI engineering, analytics, intelligent systems, and data platforms |
| Engagement Model | End-to-end Software Development Outsourcing |
Consulting-led implementation and transformation initiatives |
Engineering-focused collaboration and solution development |
| Foundation Model Expertise | Open-source and commercial foundation models |
Enterprise AI and conversational model ecosystems |
AI and machine learning model ecosystems |
| Knowledge Integration Approach | Proprietary data training and workflow-aware customization |
Knowledge management and operational enablement |
Data-centric intelligence and analytical systems |
| Deployment & MLOps Support | Model deployment, monitoring, governance, and lifecycle management |
Enterprise implementation and integration support |
Infrastructure and engineering support |
| AI Agent Capabilities | Task-oriented assistants, workflow agents, and knowledge agents |
Conversational assistants and workflow automation solutions |
Intelligent automation systems and AI-driven applications |
| Post-Deployment Involvement | Optimization, retraining recommendations, and performance monitoring |
Ongoing support based on engagement scope |
Continuous engineering and enhancement support |
| Typical Team Composition | AI engineers, data specialists, MLOps professionals, and implementation teams |
Consultants, architects, and implementation specialists |
AI engineers, data scientists, and platform developers |
| AI Deployment Preference | Cloud, private cloud, hybrid environments, and enterprise infrastructure |
Enterprise platforms, business systems, and workflow ecosystems |
Data platforms, AI infrastructure, and product-centric environments |
| Ideal Team Size | • Startups |
• Mid-market organizations and enterprises |
• Growth-stage companies and enterprises |
| AI Expertise Focus Areas | • Natural Language Processing (30%) |
• Chatbots & Conversational AI (40%) |
• Computer Vision (20%) |
Why is eSparkBiz Best Fitfor LLM Fine-Tuning Expertise?
Different providers bring valuable expertise across the AI landscape. eSparkBiz is often the best for organizations seeking LLM fine-tuning, deployment support, and long-term model optimization within a single engagement.
Not sure which Partner best aligns with your goals? Connect with Our LLM specialists for tailored guidance
Technology Stack
Technologies We Use for High-Performance LLM Fine-Tuning
Many AI initiatives struggle due to fragmented tooling. Our carefully selected technology stack supports faster development, stronger governance, and production-ready deployments.
- Models
- Assistants
- Frameworks
- Database
- Cloud
- DevOps
- Testing
We leverage Stable Diffusion to engineer photorealistic generative visuals, enabling hyper-personalized content, scalable creative automation, and immersive digital experiences across advanced platforms.
Our Claude AI implementations deliver advanced conversational intelligence, enabling context-aware automation, secure enterprise workflows, and highly accurate content generation across applications.
We utilize Generative Adversarial Networks to create high-fidelity synthetic data, enhancing simulations, visual generation, and model robustness across complex digital environments.
Our LLaMA implementations enable efficient large language modeling, delivering domain-specific intelligence, optimized performance, and scalable AI solutions for enterprise-grade applications.
We integrate OpenAI capabilities to deliver advanced language intelligence, enabling intelligent automation, contextual interactions, and scalable AI-driven innovation across enterprise applications.
Our PaLM2 integrations avail advanced reasoning and multilingual fluency, enabling precise contextual outputs, adaptive intelligence, and scalable enterprise-grade AI solutions across domains.
We deploy Gemini to orchestrate multimodal intelligence, aligning text, vision, and structured data for precise reasoning, adaptive outputs, and enterprise-grade AI performance.
We employ DeepSeek to enhance logic-intensive workflows, enabling high-precision reasoning, accelerated code generation, and consistent performance across complex enterprise-scale engineering environments.
We leverage Mistral AI capabilities to build high-performance generative solutions enabling efficient reasoning scalable models and intelligent automation workflows.
We leverage Midjourney expertise to create high-quality AI-generated visuals, enabling rapid design exploration and creative production workflows.
Our expert team uses Tabnine for effective predictive code suggestions.
We develop AI applications faster with GitHub Copilot’s contextual code generation.
We accelerate AI coding with Qodo Capabilities to delivery faster & result-driven solutions.
Our developers use Cursor’s intelligent coding capabilities for quick & enhanced coding functionalities.
We engineer solutions using Meta AI to deliver modular architectures, accelerated model iteration, and resilient AI systems optimized for large-scale enterprise deployment.
We apply CodeWhisperer to accelerate secure code generation, enabling context-aware suggestions, improving developer productivity, and maintaining consistent coding standards across enterprise projects.
We deploy Grok for real-time reasoning across dynamic data streams, delivering precise insights, rapid decision support, and adaptive intelligence for high-velocity enterprise environments.
We power Perplexity-driven intelligence to synthesize real-time knowledge, enabling precise research insights, contextual clarity, and accelerated decision-making across complex enterprise environments.
Our expertise in ToolJet streamline internal tool development, enabling rapid application building, seamless integrations, and efficient workflow automation across enterprise systems.
We leverage Replit to enable collaborative development environments, accelerating rapid prototyping, real-time coding, and seamless deployment across modern cloud-based application workflows.
Our expertise in Lovable drives faster development cycles improved code quality and smarter engineering productivity outcomes.
Our expertise in Qwen drives next-gen intelligent applications combining deep contextual understanding rapid inference and enterprise-ready AI transformation at scale.
With Python we can make beautiful, versatile apps like web or data analysis apps, with clean and easy to maintain code.
High-level Python framework for rapid development of secure web apps.
A micro web framework for Python that is used for creating web applications.
Node.js brings scalability to network applications that can handle asynchronous jobs effortlessly.
Express.js helps us create fast, scalable server side applications which can handle web requests and APIs with ease.
Using .NET, eSparkBiz develops scalable and high performance applications for your business needs that are seamlessly integrated and secured.
Practice
8+
Workforce
60+
Leveraging React.js, we build interactive and highly-scalable web app solutions with the ability to attain optimized performance seamlessly.
Our Core ML implementations power on-device intelligence, enabling low-latency predictions, enhanced data privacy, and seamless integration of machine learning within high-performance iOS applications.
For building reliable, high performance relational databases, we use MySQL to efficiently manage your data.
PostgreSQL is used by eSparkBiz to build advanced open source relational databases with extensibility and SQL compliance for complex applications.
Using MongoDB, we can create flexible and scalable NoSQL databases that fit your needs for data models.
Elasticsearch allows us to employ at our disposal powerful search and analytics capabilities to retrieve data and improve the user experience.
We use Redis to store in memory data structures and get high speed data retrieval and application responsiveness.
Cassandra’s distributed database capabilities allow us to manage large scale data workloads and provide high availability and scalability for your applications.
DynamoDB is something we know very well, so we can build scalable, low latency data solutions with high availability for your applications.
With Firebase, we have the know-how to make real time apps, seamlessly syncing data and authenticating users.
We utilize Google Cloud to deliver scalable, data-driven solutions, enabling high-performance computing, advanced analytics, and seamless infrastructure management for modern enterprises.
Our IBM Cloud expertise supports secure, scalable deployments with hybrid cloud capabilities, enabling enterprise innovation, compliance, and efficient workload management.
We leverage Oracle Cloud to deliver high-performance enterprise solutions, ensuring scalability, security, and optimized database management across mission-critical business applications.
AWS Developer Tools are used by eSparkBiz to simplify development workflow and achieve continuous integration and delivery to ensure the software is released faster and more reliably.
Secure, scalable, and efficient AWS cloud integrations.
We leverage Amazon Web Services to build scalable, secure, and high-performance cloud solutions, supporting enterprise transformation with flexible infrastructure and advanced capabilities.
We leverage Amazon ECS to orchestrate containerized applications efficiently, ensuring scalable deployments, high availability, and seamless integration across enterprise environments.
Our Amazon EKS expertise enables secure Kubernetes orchestration, delivering scalable, resilient, and automated container management aligned with enterprise-grade deployment and governance standards.
This service provides relational database management with setup simplicity, scaling capabilities and automated administration functions.
We leverage Azure AKS to deploy, manage, and scale Kubernetes clusters efficiently, ensuring secure, automated, and high-performance container orchestration across enterprise environments.
The NoSQL database solution delivers multi region capabilities and low latency performance across distributed global networks.
We are experts in Azure DevOps and we know how to make things work together smoothly, automate workflows, increase productivity and shorten project timelines.
Microsoft’s powerful tools for cloud and on-premise integrations
We use Azure SQL Database to offer scalable, high performing data solutions that ensure your applications have secure and effective data management.
Our Azure expertise enables enterprise-grade cloud solutions, ensuring scalability, security, and seamless integration across applications, data, and services within dynamic business environments.
We utilize Google Kubernetes Engine to deploy, manage, and scale containerized workloads efficiently with automated operations, ensuring reliability, performance, and infrastructure optimization.
To increase the performance of our application, we make use of Google Developer Tools so that debugging and optimization processes take place more efficiently.
With Kubernetes, we are able to orchestrate containerized applications, automatically deploy, scale, and manage your services.
Jenkins helps us automate the build and deployment process so that your projects are continuously integrated and delivered.
Our GitLab expertise enables streamlined DevOps workflows, continuous integration, and efficient version control, supporting faster delivery cycles and improved collaboration across development teams.
With our Prometheus proficiency, we can deploy reliable monitoring and alerting systems to get real time insights into how your application is performing.
Grafana is used by eSparkBiz for monitoring and observability to see system performance and health through insightful visualizations.
Ansible automates IT workflows and our proficiency allows us to achieve faster deployments (50% reduction) and better system reliability.
For build and deployment processes we use TeamCity to automate build and delivery to your projects.
Our CircleCI expertise supports scalable CI/CD pipelines, enabling rapid testing, deployment automation, and consistent delivery of high-quality applications across environments.
We utilize Travis CI for automated testing and continuous integration, ensuring faster code validation, seamless deployments, and reliable application delivery pipelines.
Puppet is used by us for configuration management automation, increasing system reliability and reducing manual intervention in deployments.
eSparkBiz uses CHEF to automate the infrastructure configuration to reduce the deployment time by up to 50% and increase the system's reliability.
SaltStack helps us automate IT operations by managing configuration and remote execution for infrastructure management.
Docker is used by eSparkBiz to containerize applications so that application environments are consistent and deployment processes are smooth.
Real time data processing and integration require this distributed event streaming platform.
We use Selenium to automate web application testing, ensuring consistent functionality, cross-browser compatibility, and accelerated quality assurance across dynamic digital platforms.
We leverage Pytest for efficient Python testing, ensuring scalable test automation, simplified debugging, and consistent validation of application functionality across development environments.
Our JUnit5 expertise supports robust unit testing frameworks, enabling faster debugging, improved code quality, and reliable application performance through structured automated testing practices.
We use Cucumber to implement behavior-driven development, aligning technical execution with business requirements through readable test scenarios and improved stakeholder collaboration.
Our TestNG expertise enables robust automated testing frameworks, supporting parallel execution, detailed reporting, and reliable validation of complex application workflows across environments.
Process
How We Fine-Tune LLMs for Real-World Business Performance
Building designed AI systems requires more than model training alone. Our structured fine-tuning process transforms foundation models into reliable business assets aligned with your data, workflows, and objectives.
Requirement Discovery
Duration: 3 - 5 Days
Organizations often struggle to identify where fine-tuning creates the most value. We evaluate business goals, AI maturity, operational challenges, and technical requirements before defining a tailored implementation strategy.
Strategy & Feasibility:
- Business objective analysis
- Use case prioritization
- AI readiness assessment
- Success metric definition
- Technical feasibility review
Requirement Discovery
Dataset Preparation
Duration: 5 - 7 Days
Model performance depends heavily on data quality. Our team evaluates existing datasets, removes inconsistencies, structures information, and prepares training-ready data that supports meaningful model adaptation.
Data Engineering:
- Dataset quality assessment
- Data cleansing workflows
- Annotation support
- Knowledge extraction
- Training dataset preparation
Dataset Preparation
Model Fine-Tuning
Duration: 7 - 10 Days
Selecting the right model architecture directly impacts outcomes. We fine-tune GPT, Llama, Mistral, and other leading models using proven adaptation techniques aligned with business requirements.
Model Customization:
- Model selection strategy
- LoRA implementation
- QLoRA optimization
- Domain-specific training
- Hyperparameter tuning
Model Fine-Tuning
Quality Testing
Duration: 3 - 5 Days
Fine-tuned models require rigorous validation before deployment. We measure accuracy, consistency, and response quality while refining model behavior to support dependable real-world performance.
Performance Validation:
- Accuracy testing
- Output consistency evaluation
- Hallucination reduction checks
- Benchmark comparisons
- Model optimization cycles
Quality Testing
Solution Deployment
Duration: 3 - 5 Days
Many AI projects stall before production deployment. We integrate fine-tuned models into existing systems, workflows, and applications while ensuring scalability, reliability, and operational readiness.
Production Deployment:
- API integration
- Workflow connectivity
- Infrastructure configuration
- Security implementation
- Performance monitoring setup
Solution Deployment
Performance Monitoring
Duration: Ongoing
Business requirements evolve continuously. Our team monitors model performance, identifies improvement opportunities, and implements updates that help maintain long-term value and relevance.
Lifecycle Management:
- Model monitoring
- Performance tracking
- Retraining recommendations
- Optimization updates
- Governance oversight
Performance Monitoring
Transform business knowledge into skilled AI through a proven process
Cost Factors of LLM Fine-Tuning
What Factors Influence the Cost of LLM Fine-Tuning Services?
Most LLM fine-tuning projects range from $5,000 to $50,000+, though every initiative presents unique requirements. Drawing on our implementation experience, we help organizations plan investments around measurable business objectives.

Training Data Requirements
The quality, structure, volume, and preparation requirements of datasets significantly influence project effort. Through our data engineering expertise, we help organizations prepare training-ready datasets that support effective model learning.

Model Complexity
Different foundation models require varying levels of infrastructure, customization effort and optimization. Our specialists assess model needs to align performance expectations with available resources and budgets.

Fine-Tuning Methodology
The selected approach, whether LoRA, QLoRA, or full fine-tuning, directly impacts training resources and implementation scope. We recommend methodologies based on business goals, scalability, and efficiency.

Infrastructure Requirements
Training workloads depend on GPU resources, cloud environments, storage demands, and deployment architecture. Our team designs infrastructure strategies that support reliable, scalable, and cost-conscious AI development.

Integration Complexity
Connecting models with applications, business systems, APIs, and workflows can increase implementation effort. With extensive integration experience, we help streamline deployment across complex operational environments.

Ongoing Maintenance & Optimization
Post-deployment activities such as performance monitoring, retraining, governance, and model improvements contribute to long-term investment requirements. Our experts continuously refine models to maintain business value.
Gain visibility into project costs before development begins
Client Testimonials
What do Clients say about working with eSparkBiz?
Building reliable AI solutions requires the right expertise and execution approach. Our clients trust us to deliver use-case driven AI systems that support measurable impact.
Useful Resources
Useful Resources for LLM Fine-Tuning
We deliver curated expert knowledge-driven content, offering strategic depth, industry relevance, and actionable insights for confident technology decisions.


AI Agent Development
Develop Autonomous AI Agents Driving Business Efficiency

Artificial Intelligence
Align AI Initiatives with Measurable Business Outcomes

AI Copilot Development
Build Intelligent Copilots Accelerating Employee Performance

Adaptive AI Development
Build Self-learning AI solutions for Dynamic Environments

Generative AI Consulting
Navigate Generative AI Adoption with Strategic Expertise

Data Science
Transform Data into Actionable Intelligence for Rapid Growth
Expert Insights
Expert Insights for LLM Fine-Tuning
We actively analyze emerging technologies and applications, publishing insightful articles. Access our latest expert blogs and updates for valuable industry knowledge.
How Agentic AI and Staff Augmentation Drive High-Performing Adaptive Teams?


Robotic Process Automation in Banking: Use Cases, Benefits, Risks and Implementation

FAQs
Frequently Asked Questions
Browse answers to common questions that help clarify LLM fine-tuning concepts, expectations, and considerations.
We already use GPT. Why would we need LLM fine-tuning?
Yes, many organizations start with GPT before considering fine-tuning. Generic models often lack business context, making expert training necessary for consistent results. eSparkBiz helps align model behavior with functional needs.
- Domain-specific knowledge adaptation
- Business terminology learning
- Response consistency improvement
- Workflow-aware intelligence
- Task-specific optimization
The result is AI that better reflects how your organization operates.
Can eSparkBiz fine-tune models using our proprietary business data?
Yes. Proprietary data is often one of the most valuable assets for successful LLM fine-tuning initiatives.
Common data sources we work with include:
Knowledge Sources
- Internal documentation
- Knowledge bases
- Support conversations
- Product information
- Policy documents
Our team also helps prepare data through:
Data Preparation Activities
- Dataset assessment
- Data cleansing
- Annotation support
- Content structuring
- Quality validation
This enables eSparkBiz to create AI systems that better reflect your organization’s expertise and operational processes.
How do you determine which model is right for our use case?
Model selection depends on business objectives, infrastructure preferences, data sensitivity, and performance expectations. eSparkBiz evaluates multiple factors before recommending a training approach.
- Use case requirements
- Deployment environment
- Budget considerations
- Scalability goals
- Governance needs
- Response quality expectations
This ensures technology decisions support long-term business goals.
Can you integrate a fine-tuned model into our existing systems?
Yes, integration is a core part of most deployments. eSparkBiz connects fine-tuned models with applications, workflows, and business systems to support real-world usage.
- Enterprise applications
- Internal portals
- CRM platforms
- Customer support systems
- Knowledge management tools
- API ecosystems
Organizations gain value when AI fits existing operations.
How involved does our internal team need to be during the project?
Internal involvement is important but does not need to become a full-time responsibility. eSparkBiz manages implementation while collaborating with key stakeholders.
- Business requirement workshops
- Dataset reviews
- Validation sessions
- Feedback cycles
- Deployment planning
This balances project efficiency with organizational alignment.
What happens after the model goes live?
Post-launch support is critical for long-term success. eSparkBiz helps organizations monitor, optimize, and improve model performance after deployment.
- Performance monitoring
- Accuracy evaluations
- Optimization recommendations
- Retraining support
- Governance reviews
- Usage analytics
Ongoing improvements help sustain business value over time.
How do you ensure the quality of a fine-tuned model?
Quality assurance begins long before deployment and continues throughout the implementation lifecycle.
During model validation, our team evaluates:
Performance Metrics
- Accuracy
- Relevance
- Consistency
- Task completion quality
- Response reliability
Before production rollout, we also perform:
Validation Activities
- Benchmark testing
- Hallucination reviews
- User acceptance testing
- Output evaluation
- Governance checks
This helps ensure the model meets business expectations before it reaches end users.
How does eSparkBiz communicate project progress during engagement?
Clear communication helps prevent delays and keeps stakeholders aligned. eSparkBiz follows structured reporting practices throughout the project lifecycle.
- Regular status meetings
- Progress reporting
- Milestone tracking
- Technical updates
- Feedback reviews
- Delivery planning
Transparent collaboration supports smoother project execution.
What are LLM fine-tuning services?
LLM fine-tuning services customize pretrained language models using domain-specific data to improve accuracy, consistency, and relevance for targeted business tasks, workflows, and industry-specific applications.
How much do LLM fine-tuning services cost?
Most LLM fine-tuning projects range from $5,000 to $50,000+, depending on data quality, customization requirements, model selection, deployment complexity, and ongoing optimization needs.
Is LLM fine-tuning better than RAG?
Fine-tuning and RAG solve different problems. Fine-tuning improves model behavior and domain expertise, while RAG enhances access to changing information. Many organizations benefit from combining both approaches.
How much training data is needed for LLM fine-tuning?
Data requirements vary by AI use case, but quality matters more than volume. Well-structured datasets with relevant examples often outperform larger datasets containing inconsistent information.
Can LLM fine-tuning reduce hallucinations?
Yes, fine-tuning can reduce hallucinations when supported by high-quality training data and evaluation processes. However, no model completely eliminates hallucinations without proper governance and monitoring.
What is the difference between LoRA and full fine-tuning?
LoRA modifies a smaller portion of model parameters, reducing infrastructure costs and training time. Full fine-tuning updates the entire model and often requires greater resources.
How do businesses measure ROI from LLM fine-tuning?
Organizations typically measure ROI through operational efficiency improvements, faster task completion, reduced manual effort, increased accuracy, and stronger user adoption across business functions.
- About eSparkBiz
- Our Featured Work
- LLM Fine-Tuning Services
- Why Choose eSparkBiz?
- What Is LLM Fine-Tuning
- LLM Fine-Tuning Needs
- Strategic Benefits
- Industries We Serve
- Core Expertise
- eSparkBiz vs Deviniti vs Xenoss
- Technologies We Use
- Our LLM Fine-Tuning Process
- Cost Factors of LLM Fine-Tuning
- Client Testimonials
- Useful Resources
- Expert Insights
- FAQ
Extend, Build, and Scale with eSparkBiz
Deliver reliable software solutions with dedicated teams, flexible models, and secure development practices.
- AI-Enabled Engineering
- 400+ Skilled Developers
- Flexible Engagement Models
- Time Zone Aligned Delivery
- Enterprise-Grade Security





